
Main Takeaways
Traditional rule-building relies heavily on manual intuition and static logic, making it too slow and rigid to keep up with evolving risks and complex fraud patterns.
Strategy Factory is Binance’s custom-built AI-powered assistant that automates and streamlines rule creation and optimization, empowering analysts to build smarter, data-driven rules faster.
By combining business-aware optimization, modular rule construction, and continuous refinement, Strategy Factory delivers precise, adaptable risk detection that better protects users.

Imagine trying to spot suspicious behavior across millions of transactions. Risk teams often need to build rules like, “If a transaction comes from a high-risk country and involves a large amount, flag it for review.” But getting those rules right is tricky. Business needs are always evolving, threats change fast, and manually building logic-based rules – especially at scale – is like assembling a puzzle with thousands of shifting pieces and no clear picture to follow. That’s where Binance’s Strategy Factory comes in.
The Challenge with Traditional Rules
Most decision rules in risk and fraud detection follow a basic structure which involves a series of logic conditions, or what’s called a Boolean expression. As a basic example, let’s consider this rule to identify apples:
A: The item is a fruit
B: It tastes sweet
C: The color is red
D: Diameter > 6 cm
E: The color is green
Expression: A & B & (C || E) & D
While this rule structure – using filters like categories and number ranges – is easy to understand, things get far more complex in real-world scenarios. Analysts often deal with vague or shifting business goals, datasets containing thousands of features and millions of records, and constantly evolving user behavior and attack patterns.
To choose the right conditions, analysts typically rely on experience and manual processes: reviewing individual cases, analyzing group-level statistics, and making educated guesses about which features and thresholds to use. As a result, manually building rules can feel like playing "Where's Wally?" across billions of combinations which is a slow, manual, and often repetitive process that usually doesn’t scale well.
What is Strategy Factory?
Strategy Factory (SF) is an AI-powered rule-building assistant developed in-house at Binance to support our risk and fraud detection teams. It’s designed to enhance human expertise by helping analysts move faster, make sharper decisions, and scale their impact. Instead of relying on manual guesswork, SF automatically surfaces effective combinations of features, thresholds, and signals based on real data. It also adapts dynamically to changing behavior over time (data drift), and lets analysts fine-tune rules toward specific business goals – resulting in smarter rules, fewer false positives, and faster responses to emerging risks.
In the sections below, we’ll take a closer look under SF’s hood, from how it constructs and optimizes rules to how it powers faster, more confident risk decisions across Binance.
Decision Trees
Let’s start with a common machine learning method for generating rules: decision trees. These models classify things by asking a sequence of yes or no questions to split the data into smaller and smaller groups – like a flowchart. Each split is chosen to reduce impurity by building a checklist that helps it decide if something is based on certain features. Here’s an example of a rule a decision tree might come up with:
IF item_type == "fruit"
AND taste == "sweet"
AND (color == "red" OR color == "green")
AND 6 cm <= diameter <= 10 cm
→ Predict: apple
In simpler terms: “If it looks like an apple, tastes like an apple, and is the right size... it probably is an apple.”
Limitations
While decision trees are intuitive and work well for simple classifications (like identifying apples based on color and size), they struggle with messy real-world problems like fraud detection. In such cases, the patterns aren’t as clean or predictable. With thousands of variables, shifting behaviors, and unclear boundaries between good and bad activity, decision trees often produce overly complex rules that are hard to control. More importantly, their core function – reducing statistical impurity – doesn’t align well with the goal of catching fraud, which requires maximizing recall and spotting edge cases, not just finding the “purest” split.
Split: SF's Core Unit for Rule Construction
While decision trees often branch out into messy, hard-to-manage structures, Split keeps things focused by building one rule at a time, linearly. At each step, it scans through every possible condition – whether that’s a numerical feature like transaction amount or a categorical one like user region – and evaluates how well each one contributes to a specific business goal, such as catching more fraud or reducing false positives. This is guided by a scoring function called Global Gain, which ensures every condition added has measurable value. Then, the best-performing condition is added to the rule, and the process repeats.
Example: Classifying Apples
Split selects item_type = fruit as the first condition.
Then add color in [red, green].
Then add a diameter between 6 and 10.
To put it simply: “If it looks like a fruit, has the right colors, and is the right size – it’s probably an apple.”
Why Split is More Efficient
Unlike traditional decision trees, Split follows a single path with no unnecessary branches. This design brings two key advantages:
1. Stronger Interpretability
A flat, linear checklist like (e.g., A & B & C) has stronger interpretability as it’s far simpler to read, review, and modify than a sprawling tree with multiple nested branches. This matters because human analysts still need to validate and tune the rules – especially in risk and fraud detection, where transparency is critical.
2. Lower Computational Overhead
Computational overhead refers to the amount of time and processing power it takes to run an algorithm. Because Split doesn’t need to build, prune, or maintain a full decision tree, it runs faster and more efficiently – making it ideal for use cases like large-scale batch detection or real-time monitoring.
Trade-offs
1. Greedy Path Dependency
Split adds one condition at a time by picking the best option at each step. While this helps build rules quickly, it can also lock the rule into a narrow path early on. That means later, potentially better combinations might be missed because earlier decisions limit what comes next.
2. Limited Flexibility and Coverage
Since Split only creates a single rule path, it may struggle to capture the full diversity of patterns in complex, noisy, or fragmented datasets. This is especially important in fraud detection, where suspicious behavior doesn’t always follow one neat pattern.
FIT: Looping Split to Generate Rule Sets
To overcome the limitations of single-path rule generation, Strategy Factory uses FIT – a module designed to build a full set of complementary rules by looping through the Split process multiple times.
1. Rule set Generation
While Split creates one rule at a time, FIT orchestrates multiple Split iterations, each focusing on a different slice of the problem. This results in a rule set – a collection of simple, interpretable rules that together cover more edge cases and behavioral patterns than a single rule could.
2. Bagging for Diversity
FIT introduces bagging (short for bootstrap aggregating), where each rule is generated using a slightly different subset of the data. By intentionally leaving out random portions of the target cases during each iteration, FIT encourages the creation of diverse rule paths, reducing overlap and increasing coverage.
3. Residual Learning for Coverage
After each rule is created, matched targets (i.e., the cases that the rule successfully captured) are removed from the training pool. This way, future iterations focus on what’s still being missed – a technique known as residual learning. Over time, this helps the system patch detection gaps without sacrificing interpretability.
4. Decay Iteration for Flexibility
If the rule generation gets stuck – for example, if constraints are too strict – FIT applies a process called decay iteration, which softens some parameters to unlock more feasible solutions. This allows analysts to balance business constraints with practical coverage.
By combining these techniques, FIT enables Strategy Factory to scale from a single rule to a smart, well-rounded rule set – all while maintaining clarity, precision, and business alignment.
Global Gain: Business-Aware Utility Function for Rule Optimization
Building on FIT’s ability to generate complementary sets of rules, we introduced the Global Gain function to ensure that these rules don’t just perform well statistically, but also align with real-world business priorities to optimize directly for business-relevant outcomes such as precision and recall.
At its core, Global Gain is a customizable utility function that evaluates the marginal improvement each new rule brings to the overall rule set. Rather than treating every rule as an isolated win, it prioritizes additions that make meaningful contributions in context – eliminating redundancy and focusing on business value.
This utility function also supports cross-label optimization, enabling flexible trade-offs between precision and recall across different classes. This makes it especially effective in risk control scenarios, where teams often need to patch overlooked edge cases quickly while still preserving strong overall performance.
By embedding business logic into the optimization objective itself, Global Gain transforms rule generation into a business-aware process – ensuring each rule not only meets statistical thresholds, but delivers tangible operational impact.
Split Constraints: Injecting Business Logic into Rule Structure
Once Split is guided by the right optimization goals, the next step is ensuring each individual rule is operationally viable. This is where Split Constraints come in – allowing analysts to directly inject domain knowledge and business requirements into the rule generation process.
Split supports several types of constraints:
Sign Constraints: Enforce directional conditions like amount >, which may align with how certain risk patterns manifest.
Threshold Limits: Restrict splits to specific domain-relevant ranges, such as requiring amount > x for a known risk threshold.
Mask System: Randomly drops strong predictive features during training to reduce overfitting and improve generalizability.
These constraints give analysts fine-grained control over how rules are constructed, not just what they optimize for.
For example:
To build a rule targeting only large apples, analysts can enforce diameter > X.
To limit a rule's applicability to certain geographies, they can restrict country codes to Europe only.
Together, Global Gain and Split Constraints form a powerful business-aware framework, one that prioritizes what matters most to the business, and shapes every rule to fit within real-world operational bounds.
Squeeze and Grow: Refining Existing Rules for Better Fit
Not all rules need to be created from scratch. Once a rule has been generated – especially under business-aware constraints – Strategy Factory provides tools to further fine-tune and enhance them through Squeeze and Grow operations. Squeeze refines existing rule thresholds to optimize for better precision or recall while Grow adds new conditions to a rule if doing so improves results. These functions help evolve existing rules to meet shifting business requirements or to better adapt to new data patterns, without discarding the useful structure already in place.
Example transformations:
Original: A & B (fruit + sweet)
After Grow: A & B & C & D (fruit + sweet + diameter + smooth texture)
After Squeeze: adjusts diameter from 5-11 cm → 6-10 cm
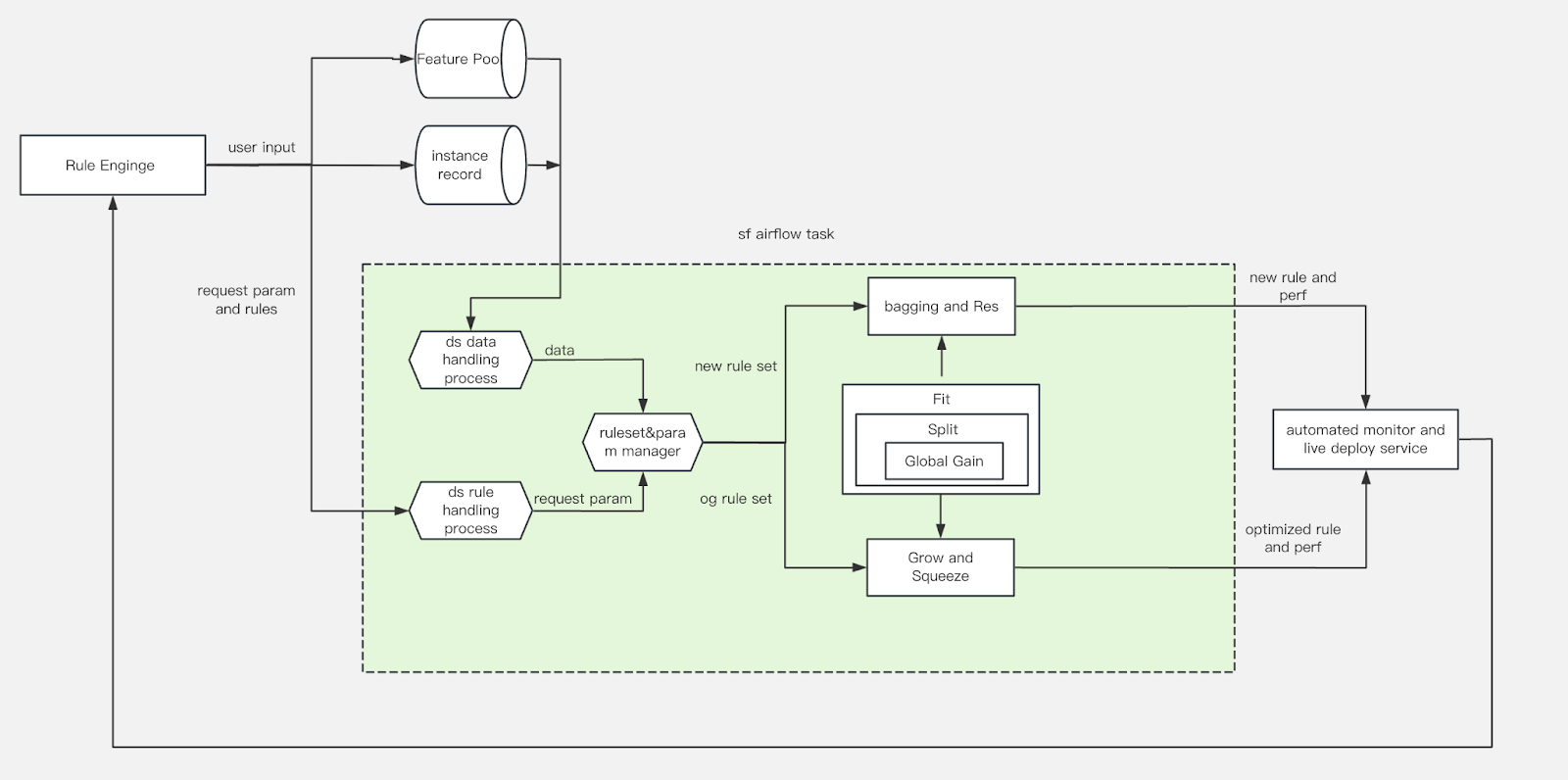
System Architecture
Strategy Factory runs as an Airflow-based pipeline designed for flexible, end-to-end rule optimization. Users configure experiments through a simple interface by selecting the event, feature set, time frame, and any constraints. This setup balances ease of use with the control needed for business-specific applications.
Once configured, the backend assembles the dataset and executes the chosen optimization method – Split, FIT, Squeeze, or Grow. The output includes the finalized rule set and monitoring estimates, which are automatically passed to the Auto Monitor UI for evaluation and deployment.
To further reduce onboarding friction, a conversational AI agent UI is in development. It will guide users through setup and interpretation, making Strategy Factory more accessible to teams with varying levels of technical expertise.
An Example of Inputs and Outputs
To understand how Strategy Factory works, let’s look at a simple example of what goes into the system and what comes out. Labeled data is divided into three categories: Negative (samples we don’t want), Positive (samples we generally want to catch), and Target (a subset of Positive – cases we want to catch but are currently missed by existing risk controls).
The samples are mapped to the available feature pool, creating a dataset table for processing. Alongside the data, users may provide requirement parameters that define rule objectives and any business or technical constraints. If we’re refining existing logic, the system also takes in the original rule content.
For example, if the task is to identify all sweet fruits, the inputs might include a labeled fruit dataset, a requirement to capture sweetness, and a prior rule for tuning. Strategy Factory then uses these inputs to generate or refine a rule that meets the goal while respecting the constraints.
For example:
Requirement: Recall = 100%
Original Rule: Color == "Red" Recall = 1 / 3 ≈ 33% Precision = 1 / 2 = 50%
In simpler terms: “If it’s red, pick it.” But out of the 3 things we wanted, it only found 1 (33% recall). And of the 2 things it picked, only 1 was actually right (50% precision).
As mentioned earlier, we use these three label types and their data to generate new rules or improve existing ones, along with estimated metrics like recall and operational impact.
In this example, the resulting optimized rule might look like this:
(Color IN ["Red", "Purple"]) AND (Sweetness > 0.75) Recall = 3 / 3 = 100% Precision = 3 / 4 = 75%
In simpler terms: “If it’s red or purple and sweet enough, it’s probably what we’re looking for.” It caught all 3 targets (100% recall), and 3 out of 4 picks were correct (75% precision).
Adoption Highlights
Strategy Factory (SF) has become an integral tool across Binance’s key risk domains, spanning login, KYC, deposits, and withdrawals, where it drives both rule creation and optimization. In the area of login protection against account takeovers, SF has reduced investigation times by 25%, while delivering newly generated rules that markedly improve both coverage and precision compared to existing ones. For withdrawal protection targeting scam prevention, SF-generated rules now represent over a quarter of all risk detections, playing a pivotal role in elevating the system’s lifting standard by 60%. These results demonstrate how SF plays a crucial role in enhancing risk controls across key Binance domains.
Roadmap
Looking ahead, we plan to onboard more event types to broaden Strategy Factory’s coverage. A key focus is launching a conversational AI agent to provide an intuitive, natural-language interface for building rules, making the system easier to use for all skill levels.
We will also integrate large language models (LLMs) to automate parameter tuning, helping optimize rules more efficiently. Alongside these advances, we aim to improve onboarding for beginners while enhancing workflows for advanced users.
Finally, we will refactor internal modules to boost modularity and performance, ensuring the system remains scalable and responsive as it grows.
Final Thoughts
Strategy Factory marks a significant evolution in rule development for risk systems – shifting from manual, intuition-driven processes to structured, AI-augmented decision-making. By equipping analysts with intelligent tools that honor business constraints while optimizing for tangible outcomes, SF effectively balances agility with control.
Looking ahead, we are committed to advancing SF with natural-language interfaces, LLM-powered auto-tuning, and stronger feedback loops that seamlessly connect detection with deployment. Our mission remains clear: to make intelligent rule generation effortless, transparent, and resilient. In doing so, we strive to better protect our users by continuously innovating and optimizing risk detection.