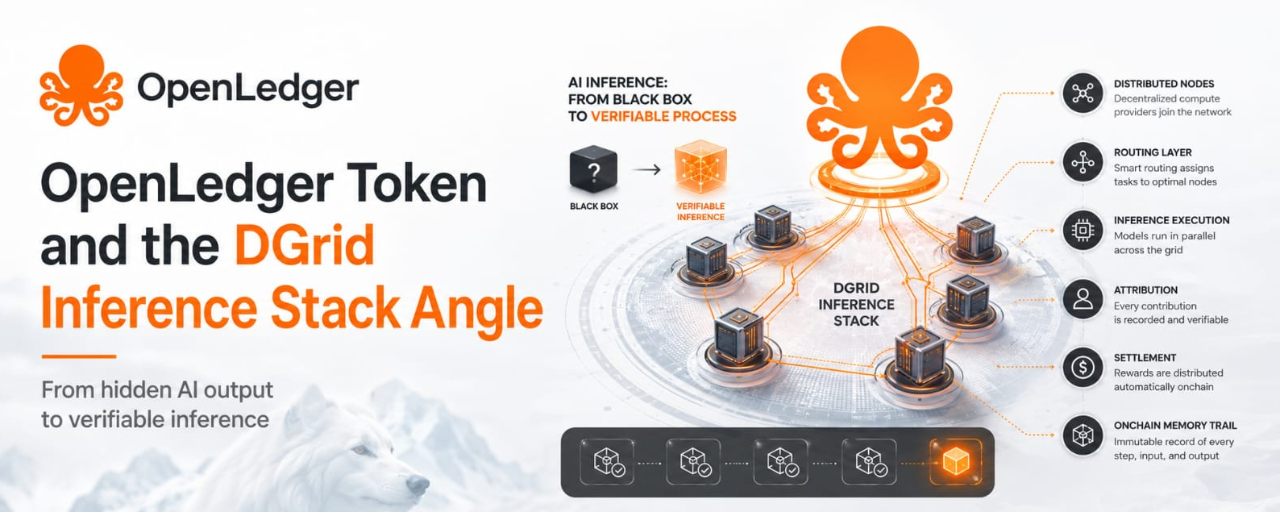

Früher dachte ich, dieser Ansatz drehe sich hauptsächlich um schnellere AI-Computing, aber diese Sichtweise erscheint mir jetzt zu eng. Nachdem ich gesehen habe, wie Inferenz beschrieben wird, ist der schwierigere Punkt nicht die Geschwindigkeit. Es ist der Speicher. DGrid erscheint oberflächlich als ein verteilter Weg für AI-Arbeiten, was bedeutet, dass Anfragen durch verschiedene Computing-Anbieter laufen können, anstatt über einen geschlossenen Serverpfad. Im Kern ist der wichtigere Wandel, dass OpenLedger möchte, dass diese Inferenzereignisse sichtbare Aufzeichnungen werden: Ausführung, Zuordnung und Abrechnung, die an einer Onchain-Spur gebunden sind. Das verändert die Frage von „Hat die AI geantwortet?“ zu „Kann das System zeigen, wie die Antwort sich bewegt hat?“
Die häufige Fehlinterpretation ist einfach: Die Leute nennen dies eine weitere AI-Token-Geschichte. Ich glaube nicht, dass das die stärkere Behauptung ist. Die stärkere Behauptung ist, dass OPEN nur dann interessant wird, wenn die Inferenz selbst sich wie ein wirtschaftliches Ereignis verhält. Inferenz bedeutet den Moment, in dem ein Modell ein Ergebnis aus einer Anfrage erzeugt. Heute sieht es oft wie ein ruhiger Serviceaufruf aus. Aber im Web3, wo Agenten handeln, leiten, bepreisen, bewerten oder automatisieren können, wird dieser ruhige Aufruf zu einer Haftungsfläche. Eine saubere Antwort reicht nicht aus, wenn niemand die Arbeitslast dahinter inspizieren kann.
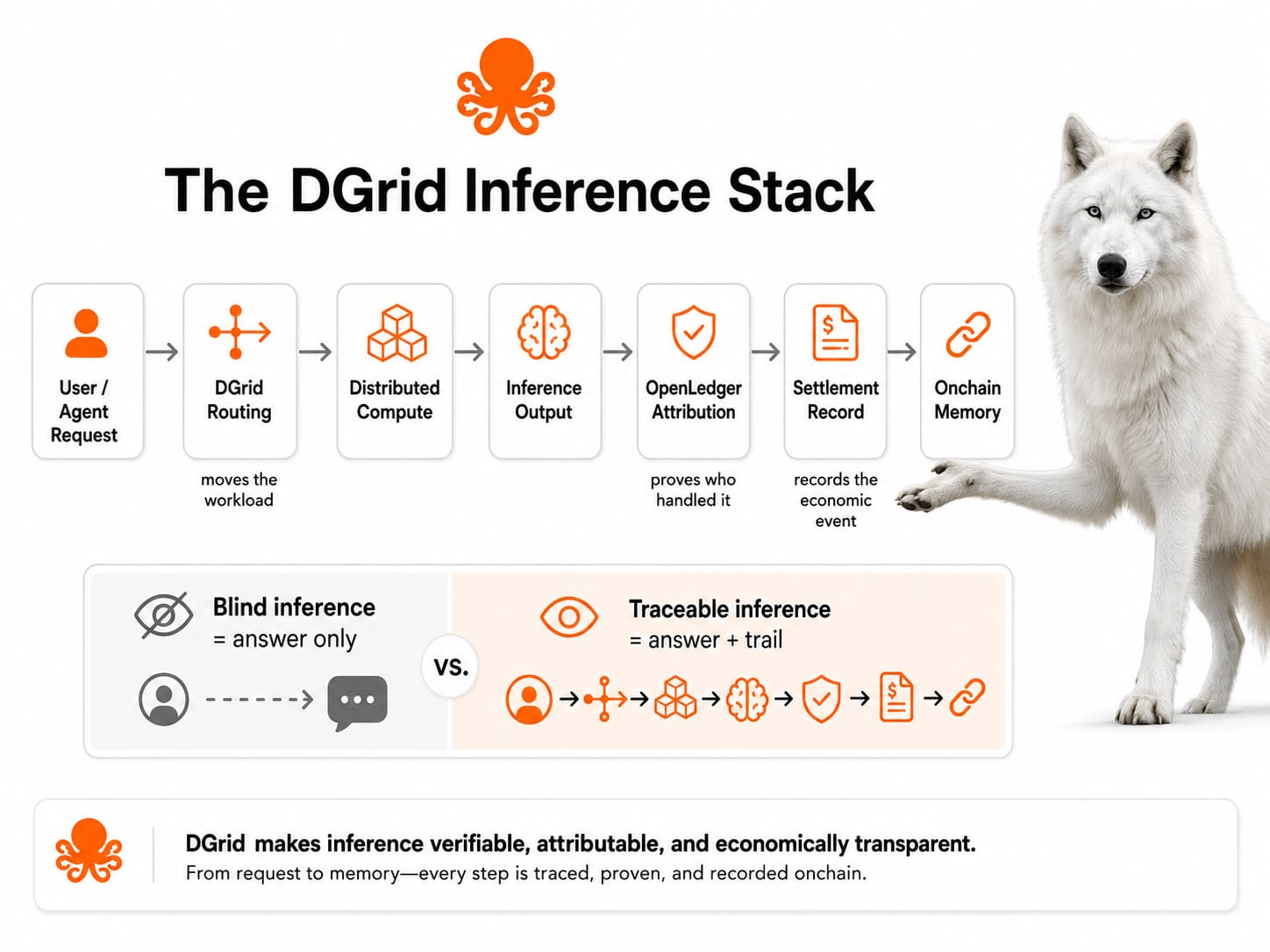
Hier kommt der DGrid-Stack ins Spiel. An der Oberfläche plant und leitet er Arbeitslasten über verteilte Berechnungen. Darunter versucht er, das Angebot an Rechenleistung flexibler zu gestalten, damit Entwickler nicht in einem Engpass der Infrastruktur stecken bleiben. Das fördert Apps, die konstanten Modellzugang, Agentenausführung und Echtzeitantworten benötigen. Aber der Preis ist die Koordination. Verteilte Berechnung kann die Spanne zwischen dem, was angefordert wurde, wer es verarbeitet hat, wie die Qualität beurteilt wurde und wer bezahlt wird, erhöhen. Ohne ein Protokoll kann Dezentralisierung zu Nebel werden, nicht zu Vertrauen.

Die Rolle von OpenLedger ist anders. Es ist nicht nur "AI-Daten". Es ist die Empfangsschicht, oder zumindest ist das die ernsthafte Version der These. Das Projekt sagt, sein Teil besteht darin, Ausführung, Zuschreibung und Abrechnung on-chain zu verankern, während DGrid den Arbeitslastweg bearbeitet. Klar gesagt, eine Schicht bewegt die Arbeit, die andere versucht, die Arbeit in Erinnerung zu behalten. Diese Struktur fördert Geschäftsmodelle, in denen verifizierte Inferenz wertvoll ist: Agenten mit Audit-Trails, Modelle mit Datenherkunft und Apps, die accountable Ausgaben benötigen. Der blinde Fleck ist ebenfalls klar: Aufzeichnungen sind nur nützlich, wenn die Aktivität darunter real, wiederholt und wert ist, aufgezeichnet zu werden.
Die Marktdaten halten mich vorsichtig 🙂. Am 31. Mai 2026 wurde OPEN in großen öffentlichen Trackern bei etwa 0,18 US-Dollar angezeigt, aber das berichtete zirkulierende Angebot war nicht vollständig konsistent: Ein Tracker zeigte etwa 215,50 Millionen OPEN, während ein anderer 290,76 Millionen OPEN anzeigte. Diese Lücke ist wichtiger als der genaue Preis, denn Small-Cap-AI-Erzählungen sind sensibel gegenüber Datenvertrauen. Ein Token mit einem Maximalangebot von 1 Milliarde hat auch zukünftigen Angebotsdruck im Hintergrund, selbst wenn die aktuelle Geschichte technisch und sauber klingt.
Das Volumen erzählt die gleiche gemischte Geschichte. Ein Tracker zeigte ungefähr 5,55 Millionen Dollar im 24-Stunden-Handel, während ein anderer über 15 Millionen Dollar anzeigte. Das ist nicht automatisch schlecht, aber es warnt mich, die Liquidität nicht als eine feststehende Wahrheit zu betrachten. In einem Markt, der immer noch von AI-gebundenen Spekulationen, Austauschströmen und konzentrierter Aufmerksamkeit des Einzelhandels geprägt ist, muss der DGrid-Winkel von OPEN mit einer härteren Realität konkurrieren: Händler könnten die Geschichte bepreisen, bevor die Infrastruktur eine dauerhafte Nachfrage beweist.
Das Gegenargument ist fair. Vielleicht ist das Ganze noch zu früh. Vielleicht klingt "verifiable inference" besser in Dokumenten als in chaotischen Produktions-Apps. Vielleicht werden die Nutzer weiterhin günstigere, schnellere Black-Box-Ausgaben wählen, bis Regulierung, Verwahrung oder Agentenausfälle sie zwingen, sich darum zu kümmern. Ich denke, dieser Skeptizismus ist gesund. Die These funktioniert nicht, weil die Worte beeindruckend sind. Sie funktioniert nur, wenn die Maschinenaktivität häufig genug wird, dass Quittungen nicht mehr optional sind.
Für jetzt könnte die stärkere Interpretation dies sein: OpenLedger versucht nicht, AI lauter zu machen. Es versucht, die unsichtbare Mitte schwerer ignorierbar zu machen. Wenn DGrid die Inferenz bewegt und OpenLedger sich daran erinnert, dann ist der echte Vermögenswert nicht nur die Antwort. Es ist die Spur hinter der Antwort, klein, langweilig und vielleicht der Teil, dem die Märkte zuletzt lernen zu vertrauen.