
Ich habe über etwas nachgedacht, das mir aufgefallen ist, während ich nachts durch On-Chain-Aktivitäten gescrollt habe, so eine Art Gewohnheit, die man entwickelt, wenn man versucht zu verstehen, wohin sich die Infrastruktur tatsächlich bewegt, anstatt nur die Preise zu beobachten. Kein Trading, kein Farming, nur zu beobachten, wie Wallets mit Systemen interagieren, die sich selten klar erklären.
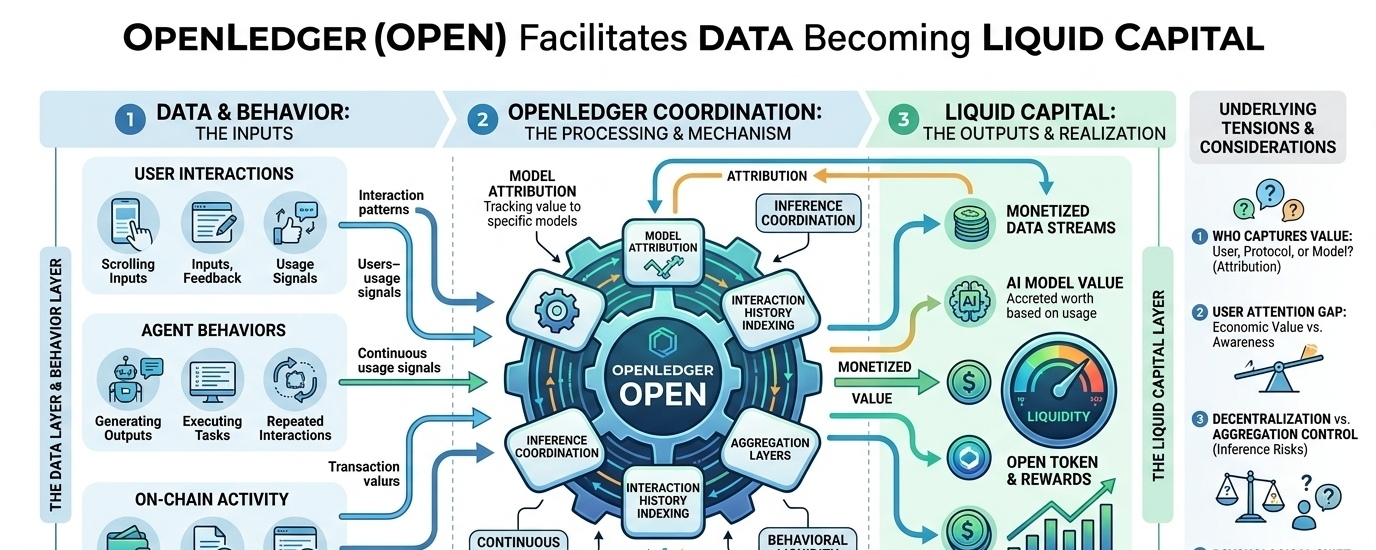
Es gibt einen stillen Wandel, bei dem Daten nicht mehr nur ein Nebeneffekt der Nutzung von Krypto-Anwendungen sind. Sie beginnen, sich mehr wie eine eigene Asset-Schicht zu verhalten. Genau da kam OpenLedger (OPEN) immer wieder in meine Gedanken, nicht wegen des Hypes, sondern weil es Daten, Modelle und Agenten als etwas darstellt, das Liquidität tragen kann.
Ich erinnere mich, als Daten in Krypto hauptsächlich Dashboards, Analysetools oder vielleicht DeFi-Metriken bedeuteten, wenn man tief genug drin war. Jetzt fühlt sich das Gespräch schwerer an, auf eine Weise, die schwer zu ignorieren ist. Es geht weniger darum, Daten zu beobachten, und mehr darum, wer den Fluss besitzt, der sie generiert.
OpenLedger befindet sich in diesem unangenehmen Zwischenraum, in dem Daten nicht nur gesammelt, sondern als etwas behandelt werden, das über KI-Systeme monetarisiert werden kann. Die Idee, dass Modelle und Agenten an Liquiditätsstrukturen teilnehmen können, erscheint mir immer noch etwas seltsam. Nicht falsch, nur vertraut genug, dass ich es immer wieder lese.
Vielleicht denke ich zu viel darüber nach, aber ich frage mich ständig, wer tatsächlich Wert erfasst, wenn ein KI-Agent Output durch wiederholte Interaktionen generiert. Ist es der Nutzer, der Input liefert, das Protokoll, das es koordiniert, oder das Modell selbst? Die Antwort scheint noch nicht endgültig zu sein, zumindest nicht auf eine klare Weise.
Was auffällt, ist, wie Liquidität in diesem Rahmen über Token und Pools hinaus auf Verhalten und Interaktionsmuster auszuweiten beginnt. Das klingt auf dem Papier abstrakt, aber es beginnt Sinn zu ergeben, wenn man darüber nachdenkt, wie KI-Systeme bereits kontinuierlich aus Nutzungssignalen lernen.
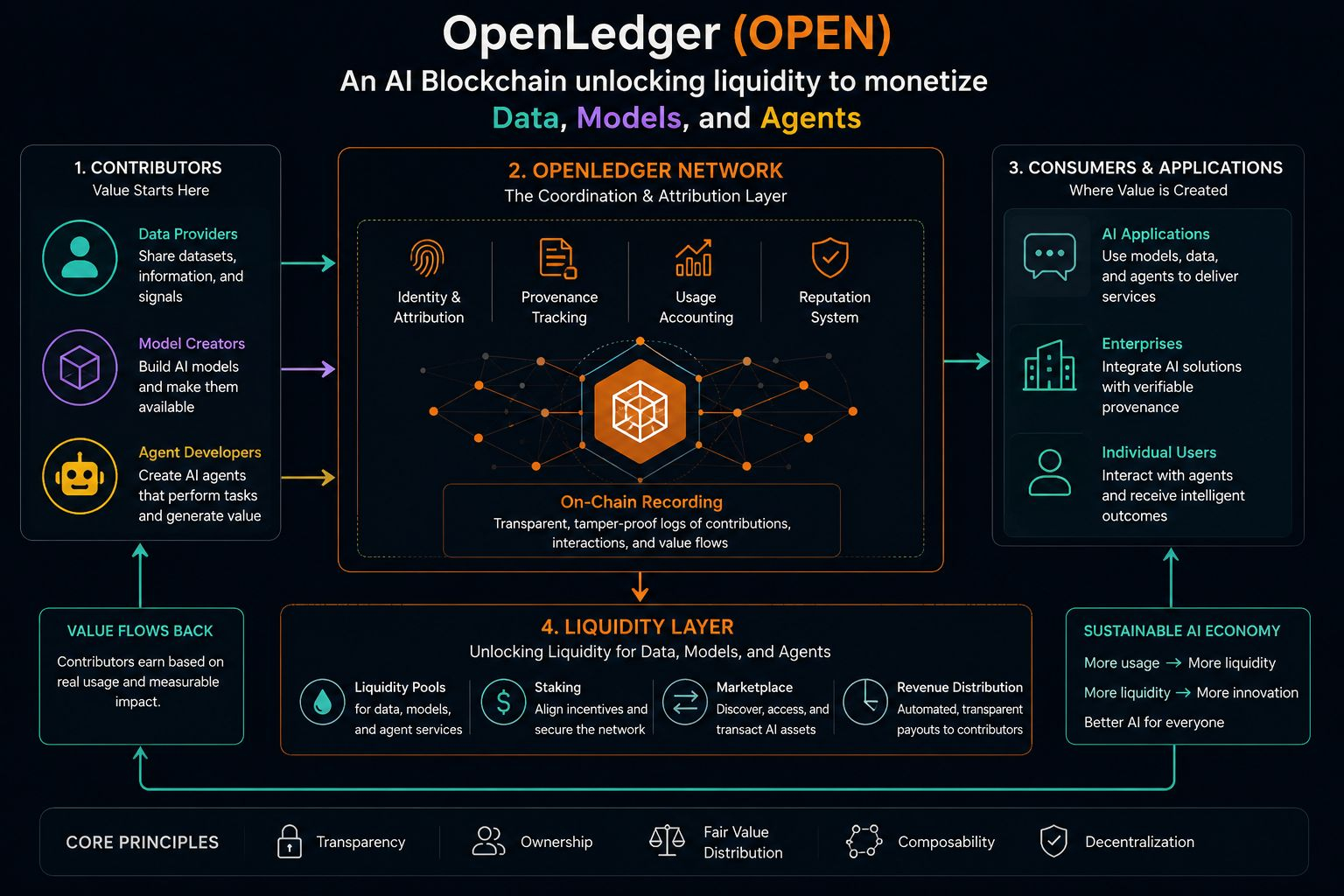
Ich habe frühere Versionen dieser Idee in fragmentierten Formen durch Datenmarktplätze und Anreizschichten gesehen, und sie stoßen normalerweise auf denselben Reibungspunkt. Die Leute wollen Eigentum an ihren Daten, aber sie wollen auch Systeme, die sie nicht zwingen, bei jedem Schritt über Eigentum nachzudenken. Diese Spannung verschwindet nie wirklich.
OpenLedger scheint zu versuchen, eine Art Kompression dieser Spannung zu erreichen, bei der Datenbeiträge, Modellinteraktionen und Attribution nicht vollständig getrennte Schichten sind. Ich bin mir jedoch nicht ganz sicher, wie sauber das in der realen Nutzung funktioniert. Es fühlt sich an wie eine dieser Ideen, die erst ihre wahre Form offenbart, wenn der Maßstab erreicht wird.
Gleichzeitig frage ich mich, ob Nutzer jemals wirklich Wert auf Attribution auf Modellebene legen werden. Die meisten Leute verfolgen heute nicht, wo ihre Daten hingehen, selbst wenn sie offensichtlich einen Wert haben. Diese Lücke zwischen wirtschaftlichem Wert und Nutzeraufmerksamkeit könnte schwerer zu überbrücken sein als die Technik selbst.
KIs, die in alltägliche Werkzeuge eingebettet werden, verändern jedoch diese Oberfläche. Sobald Systeme Entscheidungen treffen oder Aufgaben im Namen von Nutzern ausführen, wird die Interaktionshistorie wirtschaftlich relevant, egal ob Nutzer aktiv darüber nachdenken oder nicht.
Ich erinnere mich an ein ähnliches Gefühl während der frühen DeFi-Experimente, bei denen Anreize an Verhaltensweisen gekoppelt waren, die anfangs nicht natürlich wirkten. Es dauerte eine Weile, bis diese Muster normal wurden. Ich bin mir nicht sicher, ob OpenLedger dasselbe ist, aber der psychologische Wandel fühlt sich irgendwie vertraut an.
Es gibt auch eine anhaltende Unsicherheit darüber, ob dieses Modell neue Formen der Zentralisierung unter der Oberfläche einführt. Selbst wenn das System strukturell dezentralisiert ist, könnten Aggregationsschichten oder Inferenzkontrollpunkte dennoch Einfluss auf eine Weise konzentrieren, die nicht sofort sichtbar ist.
Was es schwerer macht, festzulegen, ist, ob dies eine natürliche Evolution der Krypto-Infrastruktur oder etwas ist, das hauptsächlich durch die Nachfrage nach KI geprägt wird. Es könnte beides sein, das aufeinander einwirkt, aber ich denke nicht, dass die Grenze zwischen ihnen bisher vollständig definiert ist.
Ich habe hier kein klares Fazit. Ich kreise immer wieder um die Idee, dass Daten langsam weniger wie statische Informationen und mehr wie etwas, das näher an Kapital ist, verhalten, aber in einer Form, die wir noch nicht gelernt haben, zu bewerten, darüber zu sprechen oder sogar in Echtzeit vollständig zu bemerken.
