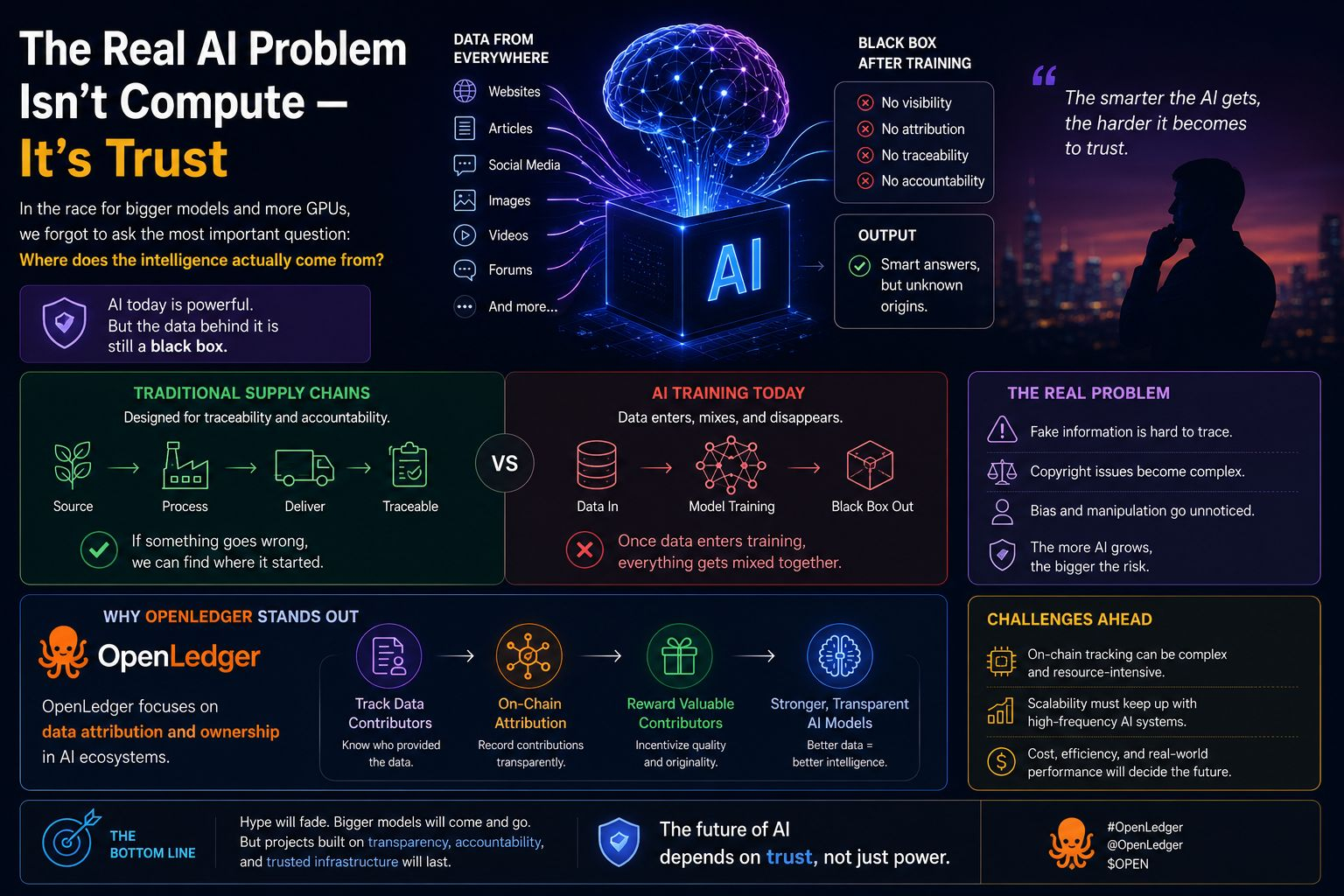
In letzter Zeit, nachdem ich viele KI-Projekte und blockchainbasierte KI-Ökosysteme erkundet habe, habe ich angefangen, über ein Problem viel tiefer nachzudenken: Vertrauen in Daten.
Die meisten Leute glauben, dass die Zukunft der KI hauptsächlich von größeren Modellen, mehr GPUs und einer stärkeren Recheninfrastruktur abhängt. Jedes neue Projekt scheint sich auf schnellere Verarbeitung, größere neuronale Netze und günstigere Rechenleistung zu konzentrieren.
Aber je mehr ich lese, desto mehr habe ich das Gefühl, dass rohe Rechenleistung nicht das größte Problem ist, dem KI langfristig gegenüberstehen wird.
Die echte Herausforderung ist Transparenz.
Die heutigen KI-Systeme werden mit enormen Mengen an Internetdaten trainiert, die aus unzähligen Quellen gesammelt wurden.
Diese Modelle können smarte Antworten, realistische Bilder und erstaunlich menschenähnliche Gespräche generieren.
Aber es gibt immer noch eine große Frage, auf die niemand eine vollständige Antwort geben kann:
Wo kommt all diese Intelligenz genau her?
Sobald Informationen in den Trainingsprozess gelangen, wird es extrem schwierig, sie zurückzuverfolgen.
Daten aus Artikeln, Webseiten, Foren, sozialen Medien, Bildern und Videos werden im Modell zusammengeführt.
Im Laufe der Zeit wird die KI leistungsfähiger, aber die Sichtbarkeit der ursprünglichen Daten wird schwächer.
Das schafft mehrere ernsthafte Bedenken.
Wenn falsche Informationen in das Modell gelangen, wird es später fast unmöglich, die Quelle zurückzuverfolgen. Dasselbe gilt für voreingenommene Inhalte, manipulierte Datensätze und urheberrechtlich geschütztes Material. Während KI immer fortschrittlicher wird, könnten diese Probleme noch größer werden, da die Menschen zunehmend auf KI-generierte Informationen im Alltag angewiesen sind.
Diese Situation erinnert mich daran, wie traditionelle Lieferketten in Branchen wie Lebensmittel, Medizin und Fertigung funktionieren.
In diesen Branchen pflegen Unternehmen normalerweise Rückverfolgbarkeitssysteme. Produkte können oft Schritt für Schritt vom Ursprung bis zur endgültigen Lieferung verfolgt werden. Wenn ein Problem auftritt, können Ermittler feststellen, wo das Problem begann und wer verantwortlich war.
Die KI-Infrastruktur funktioniert heute ganz anders.
Die meisten Modelle funktionieren wie Black Boxes, in die Daten eingegeben werden, die sich vermischen und im Trainingsprozess verschwinden, ohne dass eine klare Zuordnung erfolgt. Nutzer erhalten Ausgaben, wissen aber selten, welche Informationen zu diesen Ergebnissen beigetragen haben.
Das ist einer der Gründe, warum OpenLedger kürzlich meine Aufmerksamkeit erregt hat.
Während viele Projekte hauptsächlich um dezentrale Recheninfrastruktur konkurrieren, scheint OpenLedger auf etwas Größeres fokussiert zu sein: Datenzuordnung und -eigentum innerhalb von KI-Ökosystemen.
Die Idee selbst ist interessant, weil sie die Aufmerksamkeit von reinem Hardware-Wettbewerb ablenkt.
Anstatt nur zu fragen, wie man stärkere KI-Modelle aufbaut, erkundet das Projekt, wie Mitwirkende beweisen können, dass ihre Daten beim Training eines Modells geholfen haben und möglicherweise für wertvolle Beiträge Belohnungen erhalten. Theoretisch könnte dies eine transparentere KI-Wirtschaft schaffen, in der Datenanbieter anerkannt werden, anstatt hinter großen zentralisierten Systemen unsichtbar zu bleiben.
Natürlich stehen noch große Herausforderungen bevor.
Datenbeiträge on-chain zu verfolgen, klingt konzeptionell mächtig, aber solche Systeme effizient zu skalieren, ist nicht einfach. KI-Umgebungen verarbeiten kontinuierlich massive Datenmengen, und die Aufrechterhaltung von Zuordnungsaufzeichnungen könnte zusätzliche Kosten, Verzögerungen und technische Komplexität verursachen. Hochfrequente KI-Systeme benötigen Infrastruktur, die sowohl transparent als auch effizient in großem Maßstab bleibt.
Der echte Test für Projekte wie OpenLedger wird also nicht nur die Vision sein — es wird die Ausführung sein.
Dennoch denke ich, dass dieses Gespräch wichtig ist.
Gerade jetzt ist die KI-Branche voller Hype, Spekulation und ständiger Konkurrenz um größere Modelle. Aber wenn die Aufregung schließlich nachlässt, könnten die Projekte, die vertrauenswürdige Infrastrukturen, transparente Datensysteme und Verantwortungsmechanismen aufbauen, viel wichtiger werden, als die Leute momentan erwarten.
Langfristig könnte KI nicht einfach mehr Intelligenz benötigen.
Es könnte mehr Vertrauen benötigen.